Mysql остаток от деления. Справочное руководство по MySQL
Это еще одна часто встречающаяся задача. Основной принцип заключается в накоплении значений одного атрибута (агрегируемого элемента) на основе упорядочения по другому атрибуту или атрибутам (элемент упорядочения), возможно при наличии секций строк, определенных на основе еще одного атрибута или атрибутов (элемент секционирования). В жизни существует много примеров вычисления нарастающих итогов, например вычисление остатков на банковских счетах, отслеживание наличия товаров на складе или текущих цифр продаж и т.п.
До SQL Server 2012 решения, основанные на наборах и используемые для вычисления нарастающих итогов, были исключительно ресурсоемкими. Поэтому люди обычно обращались к итеративным решениями, которые работали небыстро, но в некоторых ситуациях все-таки быстрее, чем решения на основе наборов. Благодаря расширению поддержки оконных функций в SQL Server 2012, нарастающие итоги можно вычислять, используя простой основанный на наборах код, производительность которого намного выше, чем в старых решениях на основе T-SQL - как основанных на наборах, так и итеративных. Я мог бы показать новое решение и перейти к следующему разделу; но чтобы вы по-настоящему поняли масштаб изменений, я опишу старые способы и сравню их производительность с новым подходом. Естественно, вы вправе прочитать только первую часть, описывающую новый подход, и пропустить остальную часть статьи.
Для демонстрации разных решений я воспользуюсь остатками на счетах. Вот код, который создает и наполняет таблицу Transactions небольшим объемом тестовых данных:
SET NOCOUNT ON; USE TSQL2012; IF OBJECT_ID("dbo.Transactions", "U") IS NOT NULL DROP TABLE dbo.Transactions; CREATE TABLE dbo.Transactions (actid INT NOT NULL, -- столбец секционирования tranid INT NOT NULL, -- столбец упорядочения val MONEY NOT NULL, -- мера CONSTRAINT PK_Transactions PRIMARY KEY(actid, tranid)); GO -- небольшой набор тестовых данных INSERT INTO dbo.Transactions(actid, tranid, val) VALUES (1, 1, 4.00), (1, 2, -2.00), (1, 3, 5.00), (1, 4, 2.00), (1, 5, 1.00), (1, 6, 3.00), (1, 7, -4.00), (1, 8, -1.00), (1, 9, -2.00), (1, 10, -3.00), (2, 1, 2.00), (2, 2, 1.00), (2, 3, 5.00), (2, 4, 1.00), (2, 5, -5.00), (2, 6, 4.00), (2, 7, 2.00), (2, 8, -4.00), (2, 9, -5.00), (2, 10, 4.00), (3, 1, -3.00), (3, 2, 3.00), (3, 3, -2.00), (3, 4, 1.00), (3, 5, 4.00), (3, 6, -1.00), (3, 7, 5.00), (3, 8, 3.00), (3, 9, 5.00), (3, 10, -3.00);
Каждая строка таблицы представляет банковскую операцию на счете. Депозиты отмечаются как транзакции с положительным значением в столбце val, а снятие средств - как отрицательное значение транзакции. Наша задача - вычислить остаток на счете в каждый момент времени путем аккумулирования сумм операций в строке val при упорядочении по столбцу tranid, причем это нужно сделать для каждого счета отдельно. Желаемый результат должен выглядеть так:
Для тестирования обоих решений нужен больший объем данных. Это можно сделать с помощью такого запроса:
DECLARE @num_partitions AS INT = 10, @rows_per_partition AS INT = 10000; TRUNCATE TABLE dbo.Transactions; INSERT INTO dbo.Transactions WITH (TABLOCK) (actid, tranid, val) SELECT NP.n, RPP.n, (ABS(CHECKSUM(NEWID())%2)*2-1) * (1 + ABS(CHECKSUM(NEWID())%5)) FROM dbo.GetNums(1, @num_partitions) AS NP CROSS JOIN dbo.GetNums(1, @rows_per_partition) AS RPP;
Можете задать свои входные данные, чтобы изменить число секций (счетов) и строк (транзакций) в секции.
Основанное на наборах решение с использованием оконных функций
Я начну рассказ с решения на основе наборов, в котором используется оконная функция агрегирования SUM. Определение окна здесь довольно наглядно: нужно секционировать окно по actid, упорядочить по tranid и фильтром отобрать строки в кадре с крайней нижней (UNBOUNDED PRECEDING) до текущей. Вот соответствующий запрос:
SELECT actid, tranid, val, SUM(val) OVER(PARTITION BY actid ORDER BY tranid ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS balance FROM dbo.Transactions;
Этот код не только простой и прямолинейный - он и выполняется быстро. План этого запроса показан на рисунке:
В таблице есть кластеризованный индекс, который отвечает требованиям POC и пригоден для использования оконными функциями. В частности, список ключей индекса основан на элементе секционирования (actid), за которым следует элемент упорядочения (tranid), также для обеспечения покрытия индекс включает все остальные столбцы в запросе (val). План содержит упорядоченный просмотр, за которым следует вычисление номера строки для внутренних нужд, а затем - оконного агрегата. Так как есть POC-индекс, оптимизатору не нужно добавлять в план оператор сортировки. Это очень эффективный план. К тому же он линейно масштабируется. Позже, когда я покажу результаты сравнения производительности, вы увидите, насколько эффективнее этот способ по сравнению со старыми решениями.
До SQL Server 2012 использовались либо вложенные запросы, либо соединения. При использовании вложенного запроса нарастающие итоги вычисляются путем фильтрации всех строк с тем же значением actid, что и во внешней строке, и значением tranid, которое меньше или равно значения во внешней строке. Затем к отфильтрованным строкам применяется агрегирование. Вот соответствующий запрос:
Аналогичный подход можно реализовать с применением соединений. Используется тот же предикат, что и в предложении WHERE вложенного запроса в предложении ON соединения. В этом случае для N-ой транзакции одного и того же счета A в экземпляре, обозначенном как T1, вы будете находить N соответствий в экземпляре T2, при этом номера транзакций пробегают от 1 до N. В результате сопоставления строки в T1 повторяются, поэтому нужно сгруппировать строки по всем элементам с T1, чтобы получить информацию о текущей транзакции и применить агрегирование к атрибуту val из T2 для вычисления нарастающего итога. Готовый запрос выглядит примерно так:
SELECT T1.actid, T1.tranid, T1.val, SUM(T2.val) AS balance FROM dbo.Transactions AS T1 JOIN dbo.Transactions AS T2 ON T2.actid = T1.actid AND T2.tranid <= T1.tranid GROUP BY T1.actid, T1.tranid, T1.val;
На рисунке ниже приведены планы обоих решений:

Заметьте, что в обоих случаях в экземпляре T1 выполняется полный просмотр кластеризованного индекса. Затем для каждой строки в плане предусмотрена операция поиска в индексе начала раздела текущего счета на конечной странице индекса, при этом считываются все транзакции, в которых T2.tranid меньше или равно T1.tranid. Точка, где происходит агрегирование строк, немного отличается в планах, но число считанных строк одинаково.
Чтобы понять, сколько строк просматривается, надо учесть число элементов данных. Пусть p - число секций (счетов), а r - число строк в секции (транзакции). Тогда число строк в таблице примерно равно p*r, если считать, что транзакции распределены по счетам равномерно. Таким образом, приведенный в верхней части просмотр охватывает p*r строк. Но больше всего нас интересует происходящее в итераторе Nested Loops.
В каждой секции план предусматривает чтение 1 + 2 + ... + r строк, что в сумме составляет (r + r*2) / 2. Общее количество обрабатываемых в планах строк составляет p*r + p*(r + r2) / 2. Это означает, что число операций в плане растет в квадрате с увеличением размера секции, то есть если увеличить размер секции в f раз, объем работы увеличится примерно в f 2 раз. Это плохо. Для примера 100 строкам соответствует 10 тыс. строк, а тысяче строк соответствует миллион и т.д. Проще говоря это приводит к сильному замедлению выполнения запросов при немаленьком размере секции, потому что квадратичная функция растет очень быстро. Подобные решения работают удовлетворительно при нескольких десятках строк на секцию, но не больше.
Решения с использованием курсора
Решения на основе курсора реализуются «в лоб». Объявляется курсор на основе запроса, упорядочивающего данные по actid и tranid. После этого выполняется итеративный проход записей курсора. При обнаружении нового счета сбрасывается переменная, содержащая агрегат. В каждой итерации в переменную добавляется сумма новой транзакции, после этого строка сохраняется в табличной переменной с информацией о текущей транзакции плюс текущее значение нарастающего итога. После итеративного прохода возвращается результат из табличной переменной. Вот код законченного решения:
DECLARE @Result AS TABLE (actid INT, tranid INT, val MONEY, balance MONEY); DECLARE @actid AS INT, @prvactid AS INT, @tranid AS INT, @val AS MONEY, @balance AS MONEY; DECLARE C CURSOR FAST_FORWARD FOR SELECT actid, tranid, val FROM dbo.Transactions ORDER BY actid, tranid; OPEN C FETCH NEXT FROM C INTO @actid, @tranid, @val; SELECT @prvactid = @actid, @balance = 0; WHILE @@fetch_status = 0 BEGIN IF @actid <> @prvactid SELECT @prvactid = @actid, @balance = 0; SET @balance = @balance + @val; INSERT INTO @Result VALUES(@actid, @tranid, @val, @balance); FETCH NEXT FROM C INTO @actid, @tranid, @val; END CLOSE C; DEALLOCATE C; SELECT * FROM @Result;
План запроса с использованием курсора показан на рисунке:

Этот план масштабируется линейно, потому что данные из индекса просматриваются только раз в определенном порядке. Также у каждой операции получения строки из курсора примерно одинаковая стоимость в расчете на каждую строку. Если принять нагрузку, создаваемую при обработке одной строки курсора, равной g, стоимость этого решения можно оценить как p*r + p*r*g (как вы помните, p - это число секций, а r - число строк в секции). Так что, если увеличить число строк на секцию в f раз, нагрузка на систему составит p*r*f + p*r*f*g, то есть будет расти линейно. Стоимость обработки в расчете на строку высока, но из-за линейного характера масштабирования, с определенного размера секции это решение будет демонстрировать лучшую масштабируемость, чем решения на основе вложенных запросов и соединений из-за квадратичного масштабирования этих решений. Проведенное мной измерение производительности показало, что число, когда решение с курсором работает быстрее, равно нескольким сотням строк на секцию.
Несмотря на выигрыш в производительности, обеспечиваемый решениями на основе курсора, в общем случае их надо избегать, потому что они не являются реляционными.
Решения на основе CLR
Одно возможное решение на основе CLR (Common Language Runtime) по сути является одной из форм решения с использованием курсора. Разница в том, что вместо использования курсора T-SQL, который тратит много ресурсов на получение очередной строки и выполнение итерации, применяются итерации.NET SQLDataReader и.NET, которые работают намного быстрее. Одна из особенностей CLR которая делает этот вариант быстрее, заключается в том, что результирующая строка во временной таблице не нужна - результаты пересылаются напрямую вызывающему процессу. Логика решения на основе CLR похожа на логику решения с использованием курсора и T-SQL. Вот код C#, определяющий хранимую процедуру решения:
Using System; using System.Data; using System.Data.SqlClient; using System.Data.SqlTypes; using Microsoft.SqlServer.Server; public partial class StoredProcedures { public static void AccountBalances() { using (SqlConnection conn = new SqlConnection("context connection=true;")) { SqlCommand comm = new SqlCommand(); comm.Connection = conn; comm.CommandText = @"" + "SELECT actid, tranid, val " + "FROM dbo.Transactions " + "ORDER BY actid, tranid;"; SqlMetaData columns = new SqlMetaData; columns = new SqlMetaData("actid" , SqlDbType.Int); columns = new SqlMetaData("tranid" , SqlDbType.Int); columns = new SqlMetaData("val" , SqlDbType.Money); columns = new SqlMetaData("balance", SqlDbType.Money); SqlDataRecord record = new SqlDataRecord(columns); SqlContext.Pipe.SendResultsStart(record); conn.Open(); SqlDataReader reader = comm.ExecuteReader(); SqlInt32 prvactid = 0; SqlMoney balance = 0; while (reader.Read()) { SqlInt32 actid = reader.GetSqlInt32(0); SqlMoney val = reader.GetSqlMoney(2); if (actid == prvactid) { balance += val; } else { balance = val; } prvactid = actid; record.SetSqlInt32(0, reader.GetSqlInt32(0)); record.SetSqlInt32(1, reader.GetSqlInt32(1)); record.SetSqlMoney(2, val); record.SetSqlMoney(3, balance); SqlContext.Pipe.SendResultsRow(record); } SqlContext.Pipe.SendResultsEnd(); } } }
Чтобы иметь возможность выполнить эту хранимую процедуру в SQL Server, сначала надо на основе этого кода построить сборку по имени AccountBalances и развернуть в базе данных TSQL2012. Если вы не знакомы с развертыванием сборок в SQL Server, можете почитать раздел «Хранимые процедуры и среда CLR» в статье «Хранимые процедуры» .
Если вы назвали сборку AccountBalances, а путь к файлу сборки - "C:\Projects\AccountBalances\bin\Debug\AccountBalances.dll", загрузить сборку в базу данных и зарегистрировать хранимую процедуру можно следующим кодом:
CREATE ASSEMBLY AccountBalances FROM "C:\Projects\AccountBalances\bin\Debug\AccountBalances.dll"; GO CREATE PROCEDURE dbo.AccountBalances AS EXTERNAL NAME AccountBalances.StoredProcedures.AccountBalances;
После развертывания сборки и регистрации процедуры можно ее выполнить следующим кодом:
EXEC dbo.AccountBalances;
Как я уже говорил, SQLDataReader является всего лишь еще одной формой курсора, но в этой версии затраты на чтение строк значительно меньше, чем при использовании традиционного курсора в T-SQL. Также в.NET итерации выполняются намного быстрее, чем в T-SQL. Таким образом, решения на основе CLR тоже масштабируются линейно. Тестирование показало, что производительность этого решения становится выше производительности решений с использованием подзапросов и соединений, когда число строк в секции переваливает через 15.
По завершении надо выполнить следующий код очистки:
DROP PROCEDURE dbo.AccountBalances; DROP ASSEMBLY AccountBalances;
Вложенные итерации
До этого момента я показывал итеративные решения и решения на основе наборов. Следующее решение основано на вложенных итерациях, которые являются гибридом итеративного и основанного на наборах подходов. Идея заключается в том, чтобы предварительно скопировать строки из таблицы-источника (в нашем случае это банковские счета) во временную таблицу вместе с новым атрибутом по имени rownum, который вычисляется с использованием функции ROW_NUMBER. Номера строк секционируются по actid и упорядочиваются по tranid, поэтому первой транзакции в каждом банковском счете назначается номер 1, второй транзакции - 2 и т.д. Затем во временной таблице создается кластеризованный индекс со списком ключей (rownum, actid). Затем используется рекурсивное выражение CTE или специально созданный цикл для обработки по одной строке за итерацию во всех счетах. Затем нарастающий итог вычисляется путем суммирования значения, соответствующего текущей строке, со значением, связанным с предыдущей строкой. Вот реализация этой логики с использованием рекурсивного CTE:
SELECT actid, tranid, val, ROW_NUMBER() OVER(PARTITION BY actid ORDER BY tranid) AS rownum INTO #Transactions FROM dbo.Transactions; CREATE UNIQUE CLUSTERED INDEX idx_rownum_actid ON #Transactions(rownum, actid); WITH C AS (SELECT 1 AS rownum, actid, tranid, val, val AS sumqty FROM #Transactions WHERE rownum = 1 UNION ALL SELECT PRV.rownum + 1, PRV.actid, CUR.tranid, CUR.val, PRV.sumqty + CUR.val FROM C AS PRV JOIN #Transactions AS CUR ON CUR.rownum = PRV.rownum + 1 AND CUR.actid = PRV.actid) SELECT actid, tranid, val, sumqty FROM C OPTION (MAXRECURSION 0); DROP TABLE #Transactions;
А это реализация с использованием явного цикла:
SELECT ROW_NUMBER() OVER(PARTITION BY actid ORDER BY tranid) AS rownum, actid, tranid, val, CAST(val AS BIGINT) AS sumqty INTO #Transactions FROM dbo.Transactions; CREATE UNIQUE CLUSTERED INDEX idx_rownum_actid ON #Transactions(rownum, actid); DECLARE @rownum AS INT; SET @rownum = 1; WHILE 1 = 1 BEGIN SET @rownum = @rownum + 1; UPDATE CUR SET sumqty = PRV.sumqty + CUR.val FROM #Transactions AS CUR JOIN #Transactions AS PRV ON CUR.rownum = @rownum AND PRV.rownum = @rownum - 1 AND CUR.actid = PRV.actid; IF @@rowcount = 0 BREAK; END SELECT actid, tranid, val, sumqty FROM #Transactions; DROP TABLE #Transactions;
Это решение обеспечивает хорошую производительность, когда есть большое число секций с небольшим числом строк в секциях. Тогда число итераций небольшое, а основная работа выполняется основанной на наборах частью решения, которая соединяет строки, связанные с одним номером строки, со строками, связанными с предыдущим номером строки.
Многострочное обновление с переменными
Показанные до этого момента приемы вычисления нарастающих итогов гарантированно дают правильный результат. Описываемая в этом разделе методика неоднозначна, потому что основана на наблюдаемом, а не задокументированном поведении системы, кроме того она противоречит принципам релятивности. Высокая ее привлекательность обусловлена большой скоростью работы.
В этом способе используется инструкция UPDATE с переменными. Инструкция UPDATE может присваивать переменным выражения на основе значения столбца, а также присваивать значениям в столбцах выражение с переменной. Решение начинается с создания временной таблицы по имени Transactions с атрибутами actid, tranid, val и balance и кластеризованного индекса со списком ключей (actid, tranid). Затем временная таблица наполняется всеми строками из исходной БД Transactions, причем в столбец balance всех строк вводится значение 0,00. Затем вызывается инструкция UPDATE с переменными, связанными с временной таблицей, для вычисления нарастающих итогов и вставки вычисленного значения в столбец balance.
Используются переменные @prevaccount и @prevbalance, а значение в столбце balance вычисляется с применением следующего выражения:
SET @prevbalance = balance = CASE WHEN actid = @prevaccount THEN @prevbalance + val ELSE val END
Выражение CASE проверяет, не совпадают ли идентификаторы текущего и предыдущего счетов, и, если они равны, возвращает сумму предыдущего и текущего значений в столбце balance. Если идентификаторы счетов разные, возвращается сумма текущей транзакции. Далее результат выражения CASE вставляется в столбец balance и присваивается переменной @prevbalance. В отдельном выражении переменной ©prevaccount присваивается идентификатор текущего счета.
После выражения UPDATE решение представляет строки из временной таблицы и удаляет последнюю. Вот код законченного решения:
CREATE TABLE #Transactions (actid INT, tranid INT, val MONEY, balance MONEY); CREATE CLUSTERED INDEX idx_actid_tranid ON #Transactions(actid, tranid); INSERT INTO #Transactions WITH (TABLOCK) (actid, tranid, val, balance) SELECT actid, tranid, val, 0.00 FROM dbo.Transactions ORDER BY actid, tranid; DECLARE @prevaccount AS INT, @prevbalance AS MONEY; UPDATE #Transactions SET @prevbalance = balance = CASE WHEN actid = @prevaccount THEN @prevbalance + val ELSE val END, @prevaccount = actid FROM #Transactions WITH(INDEX(1), TABLOCKX) OPTION (MAXDOP 1); SELECT * FROM #Transactions; DROP TABLE #Transactions;
План этого решения показан на следующем рисунке. Первая часть представлена инструкцией INSERT, вторая - UPDATE, а третья - SELECT:

В этом решении предполагается, что при оптимизации выполнения UPDATE всегда будет выполняться упорядоченный просмотр кластеризованного индекса, и в решении предусмотрен ряд подсказок, чтобы предотвратить обстоятельства, которые могут помешать этому, например параллелизм. Проблема в том, что нет никакой официальной гарантии, что оптимизатор всегда будет посматривать в порядке кластеризованного индекса. Нельзя полагаться на особенности физических вычислений, когда нужно обеспечить логическую корректность кода, если только в коде нет логических элементов, которые по определению могут гарантировать такое поведение. В данном коде нет никаких логических особенностей, которые могли бы гарантировать именно такое поведение. Естественно выбор, использовать или нет этот способ, лежит целиком на вашей совести. Я считаю, что безответственно использовать его, даже если вы тысячи раз проверяли и «вроде бы все работает, как надо».
К счастью, в SQL Server 2012 этот выбор становится практически ненужным. При наличии исключительно эффективного решения с использованием оконных функций агрегирования не приходится задумываться о других решениях.
Измерение производительности
Я провел измерение и сравнение производительности различных методик. Результаты приведены на рисунках ниже:

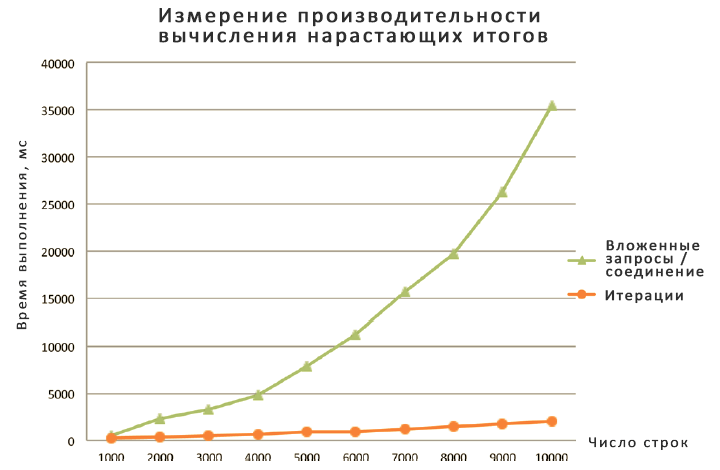
Я разбил результаты на два графика из-за того, что способ с использованием вложенного запроса или соединения настолько медленнее остальных, что мне пришлось использовать для него другой масштаб. В любом случае, обратите внимание, что большинство решений демонстрируют линейную зависимость объема работы от размера секции, и только решение на основе вложенного запроса или соединения показывают квадратичную зависимость. Также ясно видно, насколько эффективнее новое решение на основе оконной функции агрегирования. Решение на основе UPDATE с переменными тоже очень быстрое, но по описанным уже причинам я не рекомендую его использовать. Решение с использованием CLR также вполне быстрое, но в нем нужно писать весь этот код.NET и разворачивать сборку в базе данных. Как ни посмотри, а основанное на наборах решение с использованием оконных агрегатов остается самым предпочтительным.
В данной статье приведено решение оптимизации на Transact SQL задачи расчета остатки на складах. Применено: партицирование таблиц и материализованных представлений.
Постановка задачи
Задачу необходимо решить на SQL Server 2014 Enterprise Edition (x64). В фирме есть много складов. В каждом складе ежедневно по нескольку тысяч отгрузок и приемок продуктов. Есть таблица движений товаров на складе приход/расход. Необходимо реализовать:Расчет баланса на выбранную дату и время (с точностью до часа) по всем/любому складам по каждому продукту. Для аналитики необходимо создать объект (функцию, таблицу, представление) с помощью которого за выбранный диапазон дат вывести по всем складам и продуктам данные исходной таблицы и дополнительную расчетную колонку - остаток на складе позиции.
Указанные расчеты предполагаются выполняться по расписанию с разными диапазонами дат и должны работать в приемлемое время. Т.е. если необходимо вывести таблицу с остатками за последний час или день, то время выполнения должно быть максимально быстрым, равно как и если необходимо вывести за последние 3 года эти же данные, для последующей загрузки в аналитическую базу данных.
Технические подробности. Сама таблица:
Create table dbo.Turnover
(id int identity primary key,
dt datetime not null,
ProductID int not null,
StorehouseID int not null,
Operation smallint not null check (Operation in (-1,1)), -- +1 приход на склад, -1 расход со склада
Quantity numeric(20,2) not null,
Cost money not null)
Dt - Дата время поступления/списания на/со склада.
ProductID - Продукт
StorehouseID - склад
Operation - 2 значения приход или расход
Quantity - количество продукта на складе. Может быть вещественным если продукт не в штуках, а, например, в килограммах.
Cost - стоимость партии продукта.
Исследование задачи
Создадим заполненную таблицу. Для того что бы ты мог вместе со мной тестировать и смотреть получившиеся результаты, предлагаю создать и заполнить таблицу dbo.Turnover скриптом:If object_id("dbo.Turnover","U") is not null drop table dbo.Turnover;
go
with times as
(select 1 id
union all
select id+1
from times
where id < 10*365*24*60 -- 10 лет * 365 дней * 24 часа * 60 минут = столько минут в 10 лет)
, storehouse as
(select 1 id
union all
select id+1
from storehouse
where id < 100 -- количество складов)
select
identity(int,1,1) id,
dateadd(minute, t.id, convert(datetime,"20060101",120)) dt,
1+abs(convert(int,convert(binary(4),newid()))%1000) ProductID, -- 1000 - количество разных продуктов
s.id StorehouseID,
case when abs(convert(int,convert(binary(4),newid()))%3) in (0,1) then 1 else -1 end Operation, -- какой то приход и расход, из случайных сделаем из 3х вариантов 2 приход 1 расход
1+abs(convert(int,convert(binary(4),newid()))%100) Quantity
into dbo.Turnover
from times t cross join storehouse s
option(maxrecursion 0);
go
--- 15 min
alter table dbo.Turnover alter column id int not null
go
alter table dbo.Turnover add constraint pk_turnover primary key (id) with(data_compression=page)
go
-- 6 min
У меня этот скрипт на ПК с SSD диском выполнялся порядка 22 минуты, и размер таблицы занял около 8Гб на жестком диске. Ты можешь уменьшить количество лет, и количество складов, для того что бы время создания и заполнения таблицы сократить. Но какой-то неплохой объем для оценки планов запросов рекомендую оставить, хотя бы 1-2 гигабайта.
Сгруппируем данные до часа
Далее, нам нужно сгруппировать суммы по продуктам на складе за исследуемый период времени, в нашей постановке задачи это один час (можно до минуты, до 15 минут, дня. Но очевидно до миллисекунд вряд ли кому понадобится отчетность). Для сравнений в сессии (окне) где выполняем наши запросы выполним команду - set statistics time on;. Далее выполняем сами запросы и смотрим планы запросов:
Select top(1000)
convert(datetime,convert(varchar(13),dt,120)+":00",120) as dt, -- округляем до часа
ProductID,
StorehouseID,
sum(Operation*Quantity) as Quantity
from dbo.Turnover
group by
convert(datetime,convert(varchar(13),dt,120)+":00",120),
ProductID,
StorehouseID
Стоимость запроса - 12406
(строк обработано: 1000)
Время работы SQL Server:
Время ЦП = 2096594 мс, затраченное время = 321797 мс.
Если мы сделаем результирующий запрос с балансом, который считается нарастающим итогом от нашего количества, то запрос и план запроса будут следующими:
Select top(1000)
convert(datetime,convert(varchar(13),dt,120)+":00",120) as dt, -- округляем до часа
ProductID,
StorehouseID,
sum(Operation*Quantity) as Quantity,
sum(sum(Operation*Quantity)) over
(partition by StorehouseID, ProductID
order by convert(datetime,convert(varchar(13),dt,120)+":00",120)) as Balance
from dbo.Turnover
group by
convert(datetime,convert(varchar(13),dt,120)+":00",120),
ProductID,
StorehouseID

Стоимость запроса - 19329
(строк обработано: 1000)
Время работы SQL Server:
Время ЦП = 2413155 мс, затраченное время = 344631 мс.
Оптимизация группировки
Здесь достаточно все просто. Сам запрос без нарастающего итога можно оптимизировать материализованным представлением (index view). Для построения материализованного представления, то что суммируется не должно иметь значение NULL, у нас суммируются sum(Operation*Quantity), или каждое поле сделать NOT NULL или добавить isnull/coalesce в выражение. Предлагаю создать материализованное представление.
Create view dbo.TurnoverHour
with schemabinding as
select
convert(datetime,convert(varchar(13),dt,120)+":00",120) as dt, -- округляем до часа
ProductID,
StorehouseID,
sum(isnull(Operation*Quantity,0)) as Quantity,
count_big(*) qty
from dbo.Turnover
group by
convert(datetime,convert(varchar(13),dt,120)+":00",120),
ProductID,
StorehouseID
go
И построить по нему кластерный индекс. В индексе порядок полей укажем так же как и в группировке (для группировки столько порядок не важен, важно что бы все поля группировки были в индексе) и нарастающем итоге (здесь важен порядок - сначала то, что в partition by, затем то, что в order by):
Create unique clustered index uix_TurnoverHour on dbo.TurnoverHour (StorehouseID, ProductID, dt) with (data_compression=page) - 19 min
Теперь после построения кластерного индекса мы можем заново выполнить запросы, изменив агрегацию суммы как в представлении:
Select top(1000) convert(datetime,convert(varchar(13),dt,120)+":00",120) as dt, -- округляем до часа ProductID, StorehouseID, sum(isnull(Operation*Quantity,0)) as Quantity from dbo.Turnover group by convert(datetime,convert(varchar(13),dt,120)+":00",120), ProductID, StorehouseID select top(1000) convert(datetime,convert(varchar(13),dt,120)+":00",120) as dt, -- округляем до часа ProductID, StorehouseID, sum(isnull(Operation*Quantity,0)) as Quantity, sum(sum(isnull(Operation*Quantity,0))) over (partition by StorehouseID, ProductID order by convert(datetime,convert(varchar(13),dt,120)+":00",120)) as Balance from dbo.Turnover group by convert(datetime,convert(varchar(13),dt,120)+":00",120), ProductID, StorehouseID
Планы запросов стали:
 Стоимость 0.008
Стоимость 0.008
 Стоимость 0.01
Стоимость 0.01
Время работы SQL Server:
Время ЦП = 31 мс, затраченное время = 116 мс.
(строк обработано: 1000)
Время работы SQL Server:
Время ЦП = 0 мс, затраченное время = 151 мс.
Итого, мы видим, что с индексированной вьюхой запрос сканирует не таблицу группируя данные, а кластерный индекс, в котором уже все сгруппировано. И соответственно время выполнения сократилось с 321797 миллисекунд до 116 мс., т.е. в 2774 раза.
На этом бы можно было бы и закончить нашу оптимизацию, если бы не тот факт, что нам нужна зачастую не вся таблица (вьюха) а ее часть за выбранный диапазон.
Промежуточные балансы
В итоге нам нужно быстрое выполнение следующего запроса:
Set dateformat ymd;
declare
@start datetime = "2015-01-02",
@finish datetime = "2015-01-03"
select *
from
(select
dt,
StorehouseID,
ProductId,
Quantity,
sum(Quantity) over
(partition by StorehouseID, ProductID
order by dt) as Balance
from dbo.TurnoverHour with(noexpand)
where dt <= @finish) as tmp
where dt >= @start

Стоимость плана = 3103. А представь что бы было, если бы не по материализованному представлению пошел а по самой таблице.
Вывод данных материализованного представления и баланса по каждому продукту на складе на дату со временем округленную до часа. Что бы посчитать баланс - необходимо с самого начала (с нулевого баланса) просуммировать все количества до указанной последней даты (@finish), а после уже в просуммированном резалтсете отсечь данные позже параметра start .
Здесь, очевидно, помогут промежуточные рассчитанные балансы. Например, на 1е число каждого месяца или на каждое воскресенье. Имея такие балансы, задача сводится к тому, что нужно будет суммировать ранее рассчитанные балансы и рассчитать баланс не от начала, а от последней рассчитанной даты. Для экспериментов и сравнений построим дополнительный не кластерный индекс по дате:
Create index ix_dt on dbo.TurnoverHour (dt) include (Quantity) with(data_compression=page); --7 min
И наш запрос будет вида:
set dateformat ymd;
declare
@start datetime = "2015-01-02",
@finish datetime = "2015-01-03"
declare
@start_month datetime = convert(datetime,convert(varchar(9),@start,120)+"1",120)
select *
from
(select
dt,
StorehouseID,
ProductId,
Quantity,
sum(Quantity) over
(partition by StorehouseID, ProductID
order by dt) as Balance
from dbo.TurnoverHour with(noexpand)
where dt between @start_month and @finish) as tmp
where dt >
Вообще этот запрос имея даже индекс по дате полностью покрывающий все затрагиваемые в запросе поля, выберет кластерный наш индекс и сканирование. А не поиск по дате с последующей сортировкой. Предлагаю выполнить следующие 2 запроса и сравнить что у нас получилось, далее проанализируем что все-таки лучше:
Set dateformat ymd;
declare
@start datetime = "2015-01-02",
@finish datetime = "2015-01-03"
declare
@start_month datetime = convert(datetime,convert(varchar(9),@start,120)+"1",120)
select *
from
(select
dt,
StorehouseID,
ProductId,
Quantity,
sum(Quantity) over
(partition by StorehouseID, ProductID
order by dt) as Balance
from dbo.TurnoverHour with(noexpand)
where dt between @start_month and @finish) as tmp
where dt >= @start
order by StorehouseID, ProductID, dt
select *
from
(select
dt,
StorehouseID,
ProductId,
Quantity,
sum(Quantity) over
(partition by StorehouseID, ProductID
order by dt) as Balance
from dbo.TurnoverHour with(noexpand,index=ix_dt)
where dt between @start_month and @finish) as tmp
where dt >= @start
order by StorehouseID, ProductID, dt
Время работы SQL Server:
Время ЦП = 33860 мс, затраченное время = 24247 мс.(строк обработано: 145608)
(строк обработано: 1)
Время работы SQL Server:
Время ЦП = 6374 мс, затраченное время = 1718 мс.
время ЦП = 0 мс, истекшее время = 0 мс.
Из времени видно, что индекс по дате выполняется значительно быстрее. Но планы запросов в сравнении выглядят следующим образом:
Стоимость 1го запроса с автоматически выбранным кластерным индексом = 2752, а вот стоимость с индексом по дате запроса = 3119.
Как бы то не было, здесь нам требуется от индекса две задачи: сортировка и выборка диапазона. Одним индексом из имеющихся нам эту задачу не решить. В данном примере диапазон данных всего за 1 день, но если будет период больше, но далеко не весь, например, за 2 месяца, то однозначно поиск по индексу будет не эффективен из-за расходов на сортировку.
Здесь из видимых оптимальных решений я вижу:
- Создать вычисляемое поле Год-Месяц и индекс создать (Год-Месяц, остальные поля кластерного индекса). В условии where dt between @start_month and finish заменить на Год-Месяц=@месяц, и после этого уже наложить фильтр на нужные даты.
- Фильтрованные индексы - индекс сам как кластерный, но фильтр по дате, за нужный месяц. И таких индексов сделать столько, сколько у нас месяцев всего. Идея близка к решению, но здесь если диапазон условий будет из 2х фильтрованных индексов, потребуется соединение и в дальнейшем все равно сортировка неизбежна.
- Секционируем кластерный индекс так, чтобы в каждой секции были данные только за один месяц.
Секционируем кластерный индекс вьюхи. Прежде всего удалим из вьюхи все индексы:
Drop index ix_dt on dbo.TurnoverHour;
drop index uix_TurnoverHour on dbo.TurnoverHour;
И создадим функцию и схему секционирования:
Set dateformat ymd;
create partition function pf_TurnoverHour(datetime) as range right for values ("2006-01-01", "2006-02-01", "2006-03-01", "2006-04-01", "2006-05-01", "2006-06-01", "2006-07-01", "2006-08-01", "2006-09-01", "2006-10-01", "2006-11-01", "2006-12-01",
"2007-01-01", "2007-02-01", "2007-03-01", "2007-04-01", "2007-05-01", "2007-06-01", "2007-07-01", "2007-08-01", "2007-09-01", "2007-10-01", "2007-11-01", "2007-12-01",
"2008-01-01", "2008-02-01", "2008-03-01", "2008-04-01", "2008-05-01", "2008-06-01", "2008-07-01", "2008-08-01", "2008-09-01", "2008-10-01", "2008-11-01", "2008-12-01",
"2009-01-01", "2009-02-01", "2009-03-01", "2009-04-01", "2009-05-01", "2009-06-01", "2009-07-01", "2009-08-01", "2009-09-01", "2009-10-01", "2009-11-01", "2009-12-01",
"2010-01-01", "2010-02-01", "2010-03-01", "2010-04-01", "2010-05-01", "2010-06-01", "2010-07-01", "2010-08-01", "2010-09-01", "2010-10-01", "2010-11-01", "2010-12-01",
"2011-01-01", "2011-02-01", "2011-03-01", "2011-04-01", "2011-05-01", "2011-06-01", "2011-07-01", "2011-08-01", "2011-09-01", "2011-10-01", "2011-11-01", "2011-12-01",
"2012-01-01", "2012-02-01", "2012-03-01", "2012-04-01", "2012-05-01", "2012-06-01", "2012-07-01", "2012-08-01", "2012-09-01", "2012-10-01", "2012-11-01", "2012-12-01",
"2013-01-01", "2013-02-01", "2013-03-01", "2013-04-01", "2013-05-01", "2013-06-01", "2013-07-01", "2013-08-01", "2013-09-01", "2013-10-01", "2013-11-01", "2013-12-01",
"2014-01-01", "2014-02-01", "2014-03-01", "2014-04-01", "2014-05-01", "2014-06-01", "2014-07-01", "2014-08-01", "2014-09-01", "2014-10-01", "2014-11-01", "2014-12-01",
"2015-01-01", "2015-02-01", "2015-03-01", "2015-04-01", "2015-05-01", "2015-06-01", "2015-07-01", "2015-08-01", "2015-09-01", "2015-10-01", "2015-11-01", "2015-12-01",
"2016-01-01", "2016-02-01", "2016-03-01", "2016-04-01", "2016-05-01", "2016-06-01", "2016-07-01", "2016-08-01", "2016-09-01", "2016-10-01", "2016-11-01", "2016-12-01",
"2017-01-01", "2017-02-01", "2017-03-01", "2017-04-01", "2017-05-01", "2017-06-01", "2017-07-01", "2017-08-01", "2017-09-01", "2017-10-01", "2017-11-01", "2017-12-01",
"2018-01-01", "2018-02-01", "2018-03-01", "2018-04-01", "2018-05-01", "2018-06-01", "2018-07-01", "2018-08-01", "2018-09-01", "2018-10-01", "2018-11-01", "2018-12-01",
"2019-01-01", "2019-02-01", "2019-03-01", "2019-04-01", "2019-05-01", "2019-06-01", "2019-07-01", "2019-08-01", "2019-09-01", "2019-10-01", "2019-11-01", "2019-12-01");
go
create partition scheme ps_TurnoverHour as partition pf_TurnoverHour all to ();
go
Ну и уже известный нам кластерный индекс только в созданной схеме секционирования:
create unique clustered index uix_TurnoverHour on dbo.TurnoverHour (StorehouseID, ProductID, dt) with (data_compression=page) on ps_TurnoverHour(dt); --- 19 min
И теперь посмотрим, что у нас получилось. Сам запрос:
set dateformat ymd;
declare
@start datetime = "2015-01-02",
@finish datetime = "2015-01-03"
declare
@start_month datetime = convert(datetime,convert(varchar(9),@start,120)+"1",120)
select *
from
(select
dt,
StorehouseID,
ProductId,
Quantity,
sum(Quantity) over
(partition by StorehouseID, ProductID
order by dt) as Balance
from dbo.TurnoverHour with(noexpand)
where dt between @start_month and @finish) as tmp
where dt >= @start
order by StorehouseID, ProductID, dt
option(recompile);

Время работы SQL Server:
Время ЦП = 7860 мс, затраченное время = 1725 мс.
Время синтаксического анализа и компиляции SQL Server:
время ЦП = 0 мс, истекшее время = 0 мс.
Стоимость плана запроса = 9.4
По сути данные в одной секции выбираются и сканируются по кластерному индексу достаточно быстро. Здесь следует добавить то, что когда запрос параметризирован, возникает неприятный эффект parameter sniffing, лечится option(recompile).
Синтаксис SQL 2003 поддерживают все платформы.
FLOOR (выражение)
Если вы передаете в функцию положительное число, то действие функции будет состоять в удалении всего, что стоит после десятичной точки.
SELECT FLOOR(100.1) FROM dual;
Однако запомните, что в случае отрицательных чисел округление в меньшую сторону соответствует увеличению абсолютного значения.
SELECT FLOOR(-100.1) FROM dual;
Чтобы получить эффект, противоположный действию функции FLOOR, используйте функцию CEIL.
LN
Функция LN возвращает натуральный логарифм числа, то есть степень, в которую нужно возвести математическую константу е (приблизительно 2.718281), чтобы в результате получить заданное число.
Синтаксис SQL 2003
LN (выражение)
DB2, Oracle, PostgreSQL
Платформы DB2, Oracle и PostgreSQL поддерживают для функции LN синтаксис SQL 2003. DB2 и PostgreSQL также поддерживают функцию LOG как синоним LN.
MySQL и SQL Server
В MySQL и SQL Server есть своя собственная функция для вычисления натурального логарифма - LOG.
LOG (выражение)
В следующем примере для Oracle вычисляется натуральный логарифм числа, приближенно равного математической константе.
SELECT LN(2.718281) FROM dual;
Чтобы выполнить противоположную операцию, используйте функцию ЕХР.
MOD
Функция MOD возвращает остаток от деления делимого на делитель. Все платформы поддерживают синтаксис инструкции MOD стандарта SQL 2003.
Синтаксис SQL 2003
MOD (делимое, делитель)
Стандартная функция MOD предназначена для получения остатка от деления делимого на делитель. Если делитель равен нулю, то возвращается делимое.
Ниже показано, как можно использовать функцию MOD в инструкции SELECT.
SELECT MOD(12, 5) FROM NUMBERS 2;
POSITION
Функция POSITION возвращает целое число, показывающее начальное положение строки в строке поиска.
Синтаксис SQL 2003
POSITION(строка 1 IN строка2)
Стандартная функция POSITION предназначена для получения положения первого вхождения заданной строки (строка!) в строке поиска (строка!). Функция возвращает 0, если строка! не встречается в строке!, и NULL - если любой из аргументов равен NULL.
DB2
В DB2 есть эквивалентная функция POSSTR.
MySQL
Платформа MySQL поддерживает функцию POSITION в соответствии со стандартом SQL 2003.
POWER
Функция POWER используется для возведения числа в указанную степень.
Синтаксис SQL 2003
POWER (основание, показатель)
Результатом выполнения данной функции является основание, возведенное в степень, определяемую показателем. Если основание отрицательно, то показатель должен быть целым числом.
DB2, Oracle, PostgreSQL и SQL Server
Все эти производители поддерживают синтаксис SQL 2003.
Oracle
В Oracle есть эквивалентная функция INSTR.
PostgreSQL
Платформа PostgreSQL поддерживает функцию POSITION в соответствии со стандартом SQL 2003.
MySQL
Платформа MySQL поддерживает данную функциональность, не этого ключевое слово POW.
P0W (основание, показатель)
Возведение положительного числа в степень достаточно очевидно.
SELECT POWER(10.3) FROM dual;
Любое число, возведенное в степень 0, равно 1.
SELECT POWER(0.0) FROM dual;
Отрицательный показатель смещает десятичную точку влево.
SELECT POWER(10, -3) FROM dual;
SORT
Функция SQRT возвращает квадратный корень числа.
Синтаксис SQL 2003
Все платформы поддерживают синтаксис SQL 2003.
SORT (выражение)
SELECT SQRT(100) FROM dual;
WIDTH BUCKET
Функция WIDTH BUCKET присваивает значения столбцам равноширинной гистограммы.
Синтаксис SQL 2003
В следующем синтаксисе выражение представляет собой значение, которое присваивается столбцу гистограммы. Как правило, выражение основывается на одном или нескольких столбцах таблицы, возвращаемых запросом.
WIDTH BUCKET(выражение, min, max, столбцы_гистограммы)
Параметр столбцы гистограммы показывает количество создаваемых столбцов гистограммы в диапазоне значений от min до max. Значение параметра min включается в диапазон, а значение параметра max не включается. Значение выражения присваивается одному из столбцов гистограммы, после чего функция возвращает номер соответствующего столбца гистограммы. Если выражение не подпадает под указанный диапазон столбцов, функция возвращает либо 0, либо max + 1, в зависимости от того, будет выражение меньшим, чем min, или большим или равным max.
В следующем примере целочисленные значения от 1 до 10 распределяются между двумя столбцами гистограммы.
Следующий пример более интересный. 11 значений от 1 до 10 распределяются между тремя столбцами гистограммы для иллюстрации различия между значением min, которое включается в диапазон, и значением max, которое в диапазон не включается.
SELECT х, WIDTH_BUCKET(x, 1.10.3) FROM pivot;
Особое внимание обратите на результаты сХ =, Х= 9.9 и Х- 10. Входное значение параметра ими, то есть в данном примере - 1, попадает в первый столбец, обозначая нижнюю границу диапазона, поскольку столбец № 1 определяется как х >= min. Однако входное значение параметра max не входит в столбец с максимальными значениями. В данном примере число 10 попадает в столбец переполнения, с номером max + 1. Значение 9.9 попадает в столбец № 3, и это иллюстрирует правило, согласно которому верхняя граница диапазона определяется как х < max.
Все математические функции в случае ошибки возвращают NULL .
Унарный минус. Изменяет знак аргумента: mysql> SELECT - 2; -> -2 Необходимо учитывать, что если этот оператор используется с данными типа BIGINT , возвращаемое значение также будет иметь тип BIGINT ! Это означает, что следует избегать использования оператора для целых чисел, которые могут иметь величину -2^63 ! ABS(X) Возвращает абсолютное значение величины X: mysql> SELECT ABS(2); -> 2 mysql> SELECT ABS(-32); -> 32 Эту функцию можно уверенно применять для величин типа BIGINT . SIGN(X) Возвращает знак аргумента в виде -1 , 0 или 1 , в зависимости от того, является ли X отрицательным, нулем или положительным: mysql> SELECT SIGN(-32); -> -1 mysql> SELECT SIGN(0); -> 0 mysql> SELECT SIGN(234); -> 1 MOD(N,M) % Значение по модулю (подобно оператору % в C). Возвращает остаток от деления N на M: mysql> SELECT MOD(234, 10); -> 4 mysql> SELECT 253 % 7; -> 1 mysql> SELECT MOD(29,9); -> 2 Эту функцию можно уверенно применять для величин типа BIGINT . FLOOR(X) Возвращает наибольшее целое число, не превышающее X: mysql> SELECT FLOOR(1.23); -> 1 mysql> SELECT FLOOR(-1.23); -> -2 Следует учитывать, что возвращаемая величина преобразуется в BIGINT ! CEILING(X) Возвращает наименьшее целое число, не меньшее, чем X: mysql> SELECT CEILING(1.23); -> 2 mysql> SELECT CEILING(-1.23); -> -1 Следует учитывать, что возвращаемая величина преобразуется в BIGINT ! ROUND(X) Возвращает аргумент X , округленный до ближайшего целого числа: mysql> SELECT ROUND(-1.23); -> -1 mysql> SELECT ROUND(-1.58); -> -2 mysql> SELECT ROUND(1.58); -> 2 Следует учитывать, что поведение функции ROUND() при значении аргумента, равном середине между двумя целыми числами, зависит от конкретной реализации библиотеки C. Округление может выполняться: к ближайшему четному числу, всегда к ближайшему большему, всегда к ближайшему меньшему, всегда быть направленным к нулю. Чтобы округление всегда происходило только в одном направлении, необходимо использовать вместо данной хорошо определенные функции, такие как TRUNCATE() или FLOOR() . ROUND(X,D) Возвращает аргумент X , округленный до числа с D десятичными знаками. Если D равно 0 , результат будет представлен без десятичного знака или дробной части: mysql> SELECT ROUND(1.298, 1); -> 1.3 mysql> SELECT ROUND(1.298, 0); -> 1 EXP(X) Возвращает значение e (основа натуральных логарифмов), возведенное в степень X: mysql> SELECT EXP(2); -> 7.389056 mysql> SELECT EXP(-2); -> 0.135335 LOG(X) Возвращает натуральный логарифм числа X: mysql> SELECT LOG(2); -> 0.693147 mysql> SELECT LOG(-2); -> NULL Чтобы получить логарифм числа X для произвольной основы логарифмов B , следует использовать формулу LOG(X)/LOG(B) . LOG10(X) Возвращает десятичный логарифм числа X: mysql> SELECT LOG10(2); -> 0.301030 mysql> SELECT LOG10(100); -> 2.000000 mysql> SELECT LOG10(-100); -> NULL POW(X,Y) POWER(X,Y) Возвращает значение аргумента X , возведенное в степень Y: mysql> SELECT POW(2,2); -> 4.000000 mysql> SELECT POW(2,-2); -> 0.250000 SQRT(X) Возвращает неотрицательный квадратный корень числа X: mysql> SELECT SQRT(4); -> 2.000000 mysql> SELECT SQRT(20); -> 4.472136 PI() Возвращает значение числа "пи". По умолчанию представлено 5 десятичных знаков, но в MySQL для представления числа "пи" при внутренних вычислениях используется полная двойная точность. mysql> SELECT PI(); -> 3.141593 mysql> SELECT PI()+0.000000000000000000; -> 3.141592653589793116 COS(X) Возвращает косинус числа X , где X задается в радианах: mysql> SELECT COS(PI()); -> -1.000000 SIN(X) Возвращает синус числа X , где X задается в радианах: mysql> SELECT SIN(PI()); -> 0.000000 TAN(X) Возвращает тангенс числа X , где X задается в радианах: mysql> SELECT TAN(PI()+1); -> 1.557408 ACOS(X) Возвращает арккосинус числа X , т.е. величину, косинус которой равен X . Если X не находится в диапазоне от -1 до 1 , возвращает NULL: mysql> SELECT ACOS(1); -> 0.000000 mysql> SELECT ACOS(1.0001); -> NULL mysql> SELECT ACOS(0); -> 1.570796 ASIN(X) Возвращает арксинус числа X , т.е. величину, синус которой равен X . Если X не находится в диапазоне от -1 до 1 , возвращает NULL: mysql> SELECT ASIN(0.2); -> 0.201358 mysql> SELECT ASIN("foo"); -> 0.000000 ATAN(X) Возвращает арктангенс числа X , т.е. величину, тангенс которой равен X: mysql> SELECT ATAN(2); -> 1.107149 mysql> SELECT ATAN(-2); -> -1.107149 ATAN(Y,X) ATAN2(Y,X) Возвращает арктангенс двух переменных X и Y . Вычисление производится так же, как и вычисление арктангенса Y / X , за исключением того, что знаки обоих аргументов используются для определения квадранта результата: mysql> SELECT ATAN(-2,2); -> -0.785398 mysql> SELECT ATAN2(PI(),0); -> 1.570796 COT(X) Возвращает котангенс числа X: mysql> SELECT COT(12); -> -1.57267341 mysql> SELECT COT(0); -> NULL RAND() RAND(N) Возвращает случайную величину с плавающей точкой в диапазоне от 0 до 1,0 . Если целочисленный аргумент N указан, то он используется как начальное значение этой величины: mysql> SELECT RAND(); -> 0.9233482386203 mysql> SELECT RAND(20); -> 0.15888261251047 mysql> SELECT RAND(20); -> 0.15888261251047 mysql> SELECT RAND(); -> 0.63553050033332 mysql> SELECT RAND(); -> 0.70100469486881 В выражениях вида ORDER BY не следует использовать столбец с величинами RAND() , поскольку применение оператора ORDER BY приведет к многократным вычислениям в этом столбце. В версии MySQL 3.23 можно, однако, выполнить следующий оператор: SELECT * FROM table_name ORDER BY RAND() : он полезен для получения случайного экземпляра из множества SELECT * FROM table1,table2 WHERE a=b AND c
Отважные воины, не щадящие своих соратников в бою, а также жадные до чужих богатств кладоискатели! На этот раз судьба занесла вас в уединённую полуразрушенную крепость, окружённую непроходимыми лесами, топкими болотами и гейзерами с раскалённой лавой. Про
7 новых типов карт Улучшенный баланс Переписанные формулировки Планшет свалки Новые иллюстрации Обновлённый текст правил Самая знаменитая карточная игра теперь доступна и вам "Доминион" ― легендарная карточная игра, которая является одной из самых знаковы
Xbox One вышел в 2013 году, отправив на полки истории Xbox 360. Лучшие игры которого вы собрали в нашем . Владельцам новой консоли мы предлогаем наш новый Топ 20, в котором собраны Лучшие игры на Xbox One.Battlefield 1 Battlefield 1 - многопользовательски





